












Недавние тесты, проведённые OpenAI, показали, что новая модель ChatGPT o1-preview продемонстрировала относительно низкий результат, ответив корректно на 43% из 4,3 тыс. заданных вопросов. Эти вопросы касались широкого спектра тем — от кино и науки до технологий и географии. Показатель точных ответов оказался лишь на 3% ниже, чем у модели GPT-4o, что указывает на небольшой разрыв между версиями в данном тестировании.
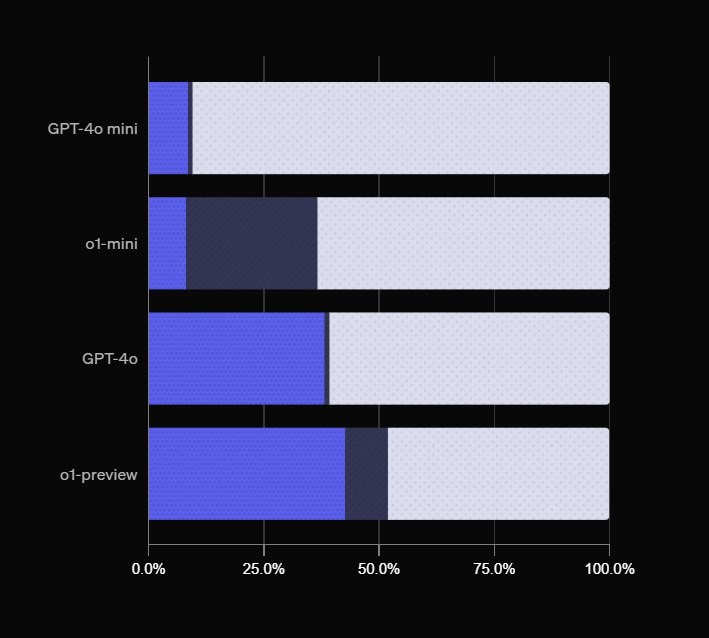

Во время теста проверялись как точность, так и уверенность ответов. Разработка таких тестов позволяет OpenAI анализировать эффективность разных моделей на задачах, связанных с обширными и узкоспециализированными знаниями. Тесты с участием тысяч вопросов помогают определить, в каких темах модели показывают лучшие результаты и в каких, возможно, требуется дальнейшая оптимизация.
Эти данные, по словам исследователей, помогут в оценке текущей версии модели и планировании улучшений в архитектуре и алгоритмах обучения. Разработчики могут использовать результаты для проведения корректировок, что в дальнейшем может повысить точность и функциональные возможности модели. Узнайте о других событиях мира технологий на нашем новостном портале.


